Managing Costs
Because Tecton manages compute and storage infrastructure in your account, your organization will be charged for the resources used to process and serve features. This section shares some best practices for keeping infrastructure costs low.
Monitoring costs using tags
Tecton will automatically apply tags to ec2 instances and dynamo tables according to the relevant feature view. By default, Tecton will apply the following tags: tecton_feature_view, tecton_workspace, and tecton_deployment.
If you would like to associate FeatureViews with various cost-centers, you can add those as tags to your FeatureView definition. Tecton will pass through those tags to any ec2 instances or dynamo tables it manages associated with the feature view.
Limiting costs during new feature development
Model training often involves large amounts of historical data to get the best results. However we rarely get features right the first time, so we need to be careful about the amount of processing and storage we use while iterating on a feature.
Note that this section focuses on features that materialize data, such as a Batch Feature View. On Demand Feature Views don't incur much infrastructure cost within Tecton.
Begin in a development workspace
The safest way to validate the logic for a new feature is to apply it to your own development workspace. Development workspaces won't run any automatic materialization jobs.
For example, when working a new feature, you may want to switch to a blank development workspace.
$ tecton workspace create my_new_feature_ws
$ tecton apply
Once applied, you can use FeatureView.get_historical_features() to view sample
output for the feature on recent dates.
import tecton
ws = tecton.get_workspace('my_new_feature_ws')
fv = ws.get_feature_view('user_has_good_credit_sql')
from datetime import datetime
from datetime import timedelta
# We need to use from_source=True because we don't have materialized data
fv.get_historical_features(start_time=(datetime.now() - timedelta(days = 7)), from_source=True)
Start with a recent feature_start_time
When you apply a Feature View to a workspace with automatic materialization
enabled, Tecton will automatically begin materializing feature data back to the
feature_start_time.
It's usually a good idea to begin with a recent start time to avoid processing a lot of historical data before you've validated that this is the right feature. For example, you may start with a week to confirm the feature output is correct and inspect how long the jobs take to complete. Next you can backfill 2 months to evaluate the performance impact on a limited set of data, and finally backfill the full 2 years once you think it is a valuable feature.
When you extend the feature start time further back, Tecton intelligently only
materializes the new dates. For example, let's say you begin with
feature_start_time=datetime(2021,1,1) . Tecton will begin with backfilling all
the data from 2021-01-01 up until the current date. If you then change to
feature_start_time=datetime(2019,1,1) to train a model with the full history,
Tecton will then only compute the data from 2019-01-01 to 2021-01-01.
Using AWS Cost Explorer, you can see the cost impact of the backfill by looking
for resources with the tecton_feature_view tag.
Keep online=False until you're ready to serve online traffic
When a feature view is configured with online=True, Tecton will materialize
data to the online store for low latency retrieval.
Online stores are optimized to provide the low latency access needs of production applications, but are an expensive place to store data.
To keep costs low you should avoid writing data to the online store until you
are ready to serve data in production. For example, you may only materialize
data offline while training and evaluating a model, then set online=True when
you're ready to deploy my model to production.
While changing from online=False to online=True will require reprocessing
historical data, the extra compute cost is typically much less than the
potential cost of backfilling to the online store twice.
Monitor materialization status, especially during backfills
Tecton will automatically retry failed jobs in case of transient issues, such as spot instance loss. However it's a good idea to keep an eye on any failures in case it is unlikely to be solved by a retry, so that you can cancel them before they are run again.
By setting your email in a MonitoringConfig, you'll get an email if there are
repeated failures. You can additionally check in the Web UI to see how jobs are
proceeding.
Note that simultaneously backfilling many feature views to the online store has been known to cause jobs to fail. Although Tecton will retry them automatically, you may want to pause some feature view backfills while others complete.
Optimizing Spark cluster configurations
Optimizing Backfills
By default, Tecton attempts to optimize the number of backfill jobs computed for each feature view. For large backfill jobs however, this default logic may not always be sufficient.
You can configure the number of days worth of data that is backfilled per job
using the max_batch_aggregation_interval parameter on feature views. This can
help reduce the amount of spark recourses needed.
The example below sets max_batch_aggregation_interval to 15 days and if
applied, will start (today - feature_start_time)/15 backfill jobs.
@batch_feature_view(
sources=[FilteredSource(transactions_batch)],
entities=[user],
mode="spark_sql",
online=True,
offline=True,
feature_start_time=datetime(2022, 5, 1),
max_batch_aggregation_interval=timedelta(days=15),
batch_schedule=timedelta(days=1),
ttl=timedelta(days=30),
description="Last user transaction amount (batch calculated)",
)
def last_transaction_amount(transactions_batch):
return f"""
SELECT
timestamp,
user_id,
amt
FROM
{transactions_batch}
"""
Streaming cluster configuration
Costs can add up quickly for streaming features because the Spark cluster is always running. If you have many streaming features, setting these options correctly will have the largest impact on your compute usage with Tecton.
If stream_cluster_config is not set, then Tecton will use a default instance
type and number of workers. You will likely want to adjust this default to fit
your production workload. Either the cluster will be under-provisioned and lead
to delayed features, or be over-provisioned and cause unnecessary costs.
How to tell if your stream cluster is over-provisioned
In short, we want to understand if the Spark cluster used for the stream processing job has excess compute or memory.
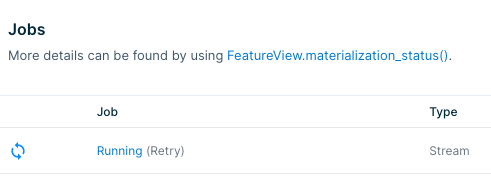
You can find the stream job associated with a feature by clicking on the Running link in the Job column in the materialization tab for the feature. This will link you to job info with your Spark provider.
From there you can find the Ganglia metrics for compute or memory usage. If the
charts show that the resources are way underutilized (e.g. CPU is 98% idle),
then you can safely reduce costs by specifying the number of workers or instance
types for your stream_cluster_config.
Batch cluster configuration
Batch processing doesn't have as much room for cost optimization as stream processing because the clusters terminate as soon as the job is done. Decreasing cluster resources may cause the jobs to take longer and offset any cost savings.
That said, you can still inspect the job logs through the link in the materialization tab shown above. If your jobs are finishing very quickly (say, less than 15 minutes), you may be spending an unnecessary amount of time spinning up the cluster and could benefit from reducing the number of workers.
Suppressing rematerialization
Rematerialization is the recreation of feature values. During this recreation, the feature values are recalculated.
Running tecton plan or tecton apply after updating a Feature View, or an
object (such as a Data Source, Transformation, or Entity) which the Feature View
depends on, will usually trigger the rematerialization of the Feature View.
If you are confident that changes to a Tecton repo will not affect feature
values, you can manually force suppress rematerialization by using the
--suppress-recreates flag when running tecton plan or tecton apply:
tecton plan --suppress-recreatestecton apply --suppress-recreates
Use the --suppress-recreates flag with caution. Only use flag when you are
confident that changes to a Tecton repo will not affect feature values. Using
the flag incorrectly can lead to inconsistent feature values.
Only workspace owners are authorized to apply plans computed with
--suppress-recreates.
Cases where you can use the flag are described below. If you are unsure about using it, please contact Tecton Support.
Use case 1: Refactoring Python functions
If you are updating a Python function in a way that does not impact feature
values, such as a refactor that adds comments or whitespace, you can use the
--suppress-recreates flag with tecton apply and tecton plan to suppress
rematerialization. The Python functions that can be changed, prior to using
--suppress-recreates, are:
The function referenced in the
post_processorparameter of thebatch_configorstream_configobject (in 0.4compatthis is theraw_batch_translatororraw_stream_translator).Example plan output when refactoring a
batch_configobject'spost_processor:↓↓↓↓↓↓↓↓↓↓↓↓ Plan Start ↓↓↓↓↓↓↓↓↓↓
~ Update BatchDataSource
name: users_batch
owner: david@tecton.ai
hive_ds_config.common_args.post_processor.body:
@@ -1,4 +1,5 @@
def post_processor(df):
+ # drop geo location columns
return df \
.drop('lat') \
.drop('long')
↑↑↑↑↑↑↑↑↑↑↑↑ Plan End ↑↑↑↑↑↑↑↑↑↑↑↑
⚠️ ⚠️ ⚠️ WARNING: This plan was computed with --suppress-recreates, which force-applies changes without causing recreation or rematerialization. Updated feature data schemas have been validated and are equal, but please triple check the plan output before applying.Transformation functions including the transformation for a Feature View.
Use case 2: Upstream Data Source migrations
If you need to perform a migration of an underlying data source that backs a
Tecton Data Source, you can use the --suppress-recreates flag with
tecton apply and tecton plan to migrate your Tecton Data Source to use the
new underlying data source, without rematerialization. This assumes the schema
and data in the new underlying data source is the same as that of the original
underlying data source.
Supported changes you can make, prior to using --suppress-recreates, are:
Updating an existing
batch_configorstream_configobject (such as aHiveConfig), where the schema and data in the underlying data source utilized by thebatch_configorstream_configobject is the same.This is useful when migrating to a replica table within the same database. Example:
↓↓↓↓↓↓↓↓↓↓↓↓ Plan Start ↓↓↓↓↓↓↓↓↓↓
~ Update BatchDataSource
name: users_batch
owner: david@tecton.ai
hive_ds_config.table: customers -> customers_replica
↑↑↑↑↑↑↑↑↑↑↑↑ Plan End ↑↑↑↑↑↑↑↑↑↑↑↑
⚠️ ⚠️ ⚠️ WARNING: This plan was computed with --suppress-recreates, which force-applies changes without causing recreating or rematerialization. Updated feature data schemas have been validated and are equal, but please triple check the plan output before applying.Replacing an existing
batch_configorstream_configobject with a new one, where the schema and data in the underlying data source utilized by the newbatch_configorstream_configobject is the same as schema of the original object.This is useful when migrating to a new data source format (e.g. from a Parquet format File Data Source to a Hive Data Source), to improve performance.
Creating a new Tecton Data Source for a new replica source, and then changing an existing Batch Feature View to use the new Data Source.
This is useful when the Data Source is used by many Feature Views and you want to migrate one at a time. Example:
↓↓↓↓↓↓↓↓↓↓↓↓ Plan Start ↓↓↓↓↓↓↓↓↓↓
+ Create BatchDataSource
name: users_batch_replica
owner: david@tecton.ai
~ Update FeatureView
name: user_date_of_birth
owner: matt@tecton.ai
description: User date of birth, entered at signup.
DependencyChanged(DataSource): -> users_batch_replica
↑↑↑↑↑↑↑↑↑↑↑↑ Plan End ↑↑↑↑↑↑↑↑↑↑↑↑
⚠️ ⚠️ ⚠️ WARNING: This plan was computed with --suppress-recreates, which force-applies changes without causing recreation or rematerialization. Updated feature data schemas have been validated and are equal, but please triple check the plan output before applying.
Special Behavior for Stream Feature Views
Tecton uses checkpointing to track position when reading from streams. When some
above changes are made to a repo with --suppress-recreates, Tecton cannot
guarantee that the current checkpoint for a Stream Feature View is valid
according to
Spark Streaming docs.
Such changes include:
- Swapping the Stream Feature View to read from a different Stream Data Source
- Modifying anything in Stream Feature View's Data Source
stream_config, except thepost_processor(raw_stream_translatorin SDK 0.4compat).
When the checkpoint for a Stream Feature View is no longer valid, the checkpoint is discarded and the current streaming job is restarted. The stream job may take some time to catch up to its previous location, temporarily affecting freshness.
Most of the time, however, changes will not invalidate the checkpoint, but may still modify the definition of the Feature View. These include:
- Modifying the Stream Data Source's
stream_config'spost_processorfunction - Modifying any transformation function in a Stream Feature View's pipeline, including its primary transformation.
In these cases, the current streaming job is restarted to use the new definition of the Feature View, but the checkpoint is re-used. The stream job may take some time to catch up to its previous location, temporarily affecting freshness.
When in doubt, the output of tecton plan/apply --suppress-recreates will
display all intended changes to the streaming materialization job for review
before applying.
Special Behavior for Updating the ttl Value in Feature Views
Updating the ttl value in a Feature View (assuming offline or online are
set to True) will result in a destructive recreate. If you want to decrease
the ttl value, but avoid re-materialization, you should use
--suppress-recreates flag when running tecton plan/tecton apply to prevent
recomputing your feature values. However, when you want to increase the ttl
value, you cannot use --suppress-recreates and you will have to
re-materialize.
Unsupported use cases
Recreates cannot be suppressed if any of the following occurs, and will result in a plan failure:
- Modification of the schema (such as adding a column or removing a column) of a Feature View.
- Modification of the schema of the
RequestSourceobject that is used in an On-Demand Feature View. - Modification of any Stream Feature View with tiled (non-continuous) window aggregates, when the Feature View's checkpoint is no longer valid.